
Jak może pamiętasz, jest tu na blogu wpis o prawach autorskich efektów pracy sztucznej inteligencji. Warto jednak zastanowić się nad tym, co dzieje się nieco wcześniej — a więc przed umieszczaniem w opartym na niej narzędziu czegoś, co może takiemu prawu podlegać. Spróbujmy zmierzyć się także z tym.
W sumie można powiedzieć, że zapowiadałem ten wpis. Poprzedni wyniknął z płatnej współpracy z firmą Literacka i tak samo zresztą jest z tym. Pisałem tam:
”No to zostaje jeszcze narzędzie BookScout.ai od Literackiej, która zainspirowała dzisiejszy wpis. Na czym polega? Wyręcza wydawców w pierwszym przeglądzie spływających do nich (wciąż tak zwanych) „rękopisów” od pragnących wypuszczenia ich książki autorów. Raport zwany Mapą Książki określa między innymi czy tekst pasuje do profilu wydawcy, kto może być zainteresowany tekstem, do jakiego pasuje gatunku, jakie wzbudza emocje i jaka jest jakość języka i styl autora. O prawach autorów książek w tym kontekście porozmawiamy sobie osobno – spodziewaj się drugiego wpisu w ciągu miesiąca”.
To ten wpis 😉
Zastanowimy się zatem nad tym, na jakich zasadach wydawnictwo może udostępnić Literackiej (i nie tylko) teksty i utwory do analizy przez sztuczną inteligencję. I szerzej – nad możliwymi dwoma scenariuszami umieszczania czegoś w magicznym pudełku „sztuczna inteligencja” w celu osiągnięcia jakiegoś zautomatyzowanego efektu.
Pierwsza możliwość
Mam tu na myśli kwestię danych, które służyły do wytrenowania modelu. Czyli nie tych, jakie użytkownik ręcznie wprowadza w narzędzie w celu osiągnięcia określonego efektu – tylko tych włożonych wcześniej po to, by sztuczna inteligencja „się nauczyła”.
Zaczynam od tego scenariusza, bo czasem – jak przy thispersondoesnotexist czy generatorach „losowej” sztuki — efekt prac określonego narzędzia w ogóle nie jest powiązany z udziałem użytkownika. I nic on od siebie nie daje, w tym nic ewentualnie objętego prawem autorskim – po prostu klika guzik typu “generuj” i maszyna robi resztę.
(A jeśli model np. stworzy dokument identyczny z wrzuconym do trenowania? Czy wynika to z tego, że „przypomniał” sobie taki dokument? Czy po prostu „trafił” jak małpy piszące Szekspira? To jednak rozważania bardziej już filozoficzne i – przynajmniej moim zdaniem — w praktyce chyba mało prawdopodobne. Natomiast wątpliwość odnośnie autorstwa „rzeczy wkładanych” jest absolutnie prawdopodobna i wręcz nieunikniona.)

Powyżej komputerowo wygenerowany obraz „autorstwa” Rembrandta. W tym przypadku włożono w „puszkę” ponad 150 tysięcy fragmentów jego prac – no ale on już nie żyje i to od zdecydowanie ponad 70 lat, zatem jego prace przeszły do domeny publicznej (o której przeczytasz tutaj). A co, gdyby żył? Bo co do efektów pracy puszki pisałem tak:
„W tworzeniu programu brali udział historycy sztuki, naukowcy, spece od sztucznej inteligencji – program »tylko« analizował podane mu rzeczy. Kontynuując myśl Panów Profesorów – Ci ludzie przesądzili o nadaniu wytworowi jakiejś cechy i są współautorami.”.
Gdyby żył — jestem zdania, że musielibyśmy się pochylić nad jego prawami autorskimi osobistymi. Dla mojej wygody posłużmy się polską ustawą, w innych rozegrane jest to podobnie. W art. 16 mowa o tym, że autor może między innymi decydować o pierwszym udostępnieniu utworu publiczności czy nadzorować sposób korzystania z utworu. Może miałbym jeszcze wątpliwości, czy „publicznością” jest sztuczna inteligencja i grupka jej twórców — ale nie mam, że „wrzucenie w puszkę” to sposób korzystania z utworu.
Mamy tu jednak kwestię tego, że mowa o „fragmentach” jego prac. I tego, że trening modelu tak naprawdę nie wymaga, by dane mu treści były jakoś specjalnie „artystyczne” – jak choćby przy modelach, których efektem jest symulowanie czyjegoś głosu. Próbki mogą być zwykłą rozmową, której określona osoba odpowiada na pytanie o drogę z dworca na rynek. Nie muszą zatem „mieć” praw autorskich.
A nawet jeśli mają — może zostały „wystarczająco” zdemontowane, że to dosłownie trzy piksele na krzyż? Albo może jesteśmy w stanie oprzeć się na prawie cytatu?
By legalnie cytować trzeba spełniać określone warunki (więcej o nich zobaczysz tutaj albo tutaj). A jeśli efekt cytowania będzie nauczał? A jeśli efekt składając się z mnóstwa fragmencików będzie rozumiany jako kolaż?
No właśnie. Najpierw niby powyżej jasna odpowiedź (“potrzebna jest zgoda”), ale zostawiam ten scenariusz z paczką wątpliwości. Przejdźmy do drugiego.
Druga możliwość
Czyli – zostawmy wkładkę służącą do stworzenia modelu czy wytrenowania sztucznej inteligencji, jak zwał tak zwał. Skupmy się na tym jednym utworze, który użytkownik wrzuca jej do obróbki. Tak jak tam wygodniej było mi posłużyć się Rembrandtem i ogólniej obrazem, tak teraz przerzucę się na narzędzia pracujące na tekście pisanym. Przykłady?
Choćby AutoCrit podpowiadający pisarzom sposoby ulepszenia tekstu czy robiący to samo od trochę innej strony Intellogo. Od strony bardziej biznesowo-naukowej przydatne jest Unsilo (łączy w nową publikację wyszukane po określonych tematach artykuły) albo asystent pisania Crimsoni.
Z kolei Savant technologicznie wspiera przypasowanie książek do „kategorii”. Ale! Przede wszystkim przykładem będą sprawcy zamieszania, czyli Literacka i ich narzędzie BookScout. Będzie ono generowało m.in. notki wydawnicze. Ponadto stworzyli oprogramowanie o nazwie Fiona, które „czyta” i analizuje utwory literackie – a następnie sztuczna inteligencja generuje wyniki w postaci tzw. mapy książki. Pokazywałem taką mapę w poprzednim wpisie, dorzucę dla wygody też teraz.
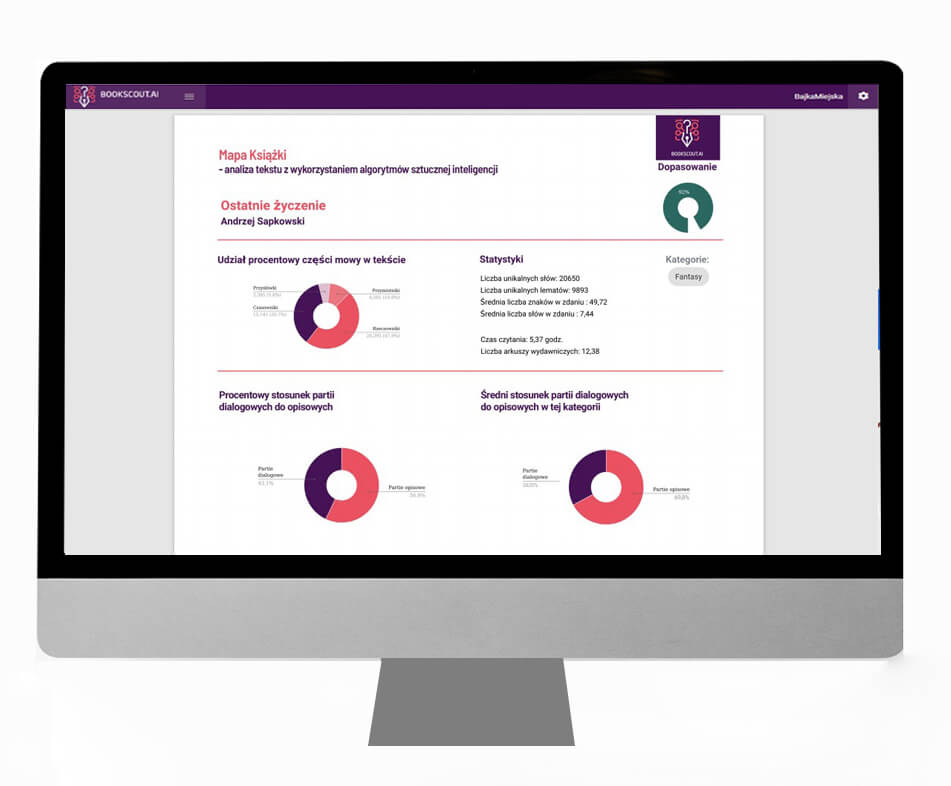
Czyli teraz pytanie brzmi — na jakich zasadach wydawnictwo może udostępnić do analizy tekst utworu autora, który dopiero wysyła swoją propozycję wydawniczą (czyli tekst nie został jeszcze opublikowany). A więc wydawnictwo chce ocenić „potencjał” tekstu – nie ma jeszcze do niego praw.
Dostało „rękopis” – czyli plik, ale nadal stosuje się tę nazwę dla odróżnienia. Dopiero podejmie decyzję, czy właśnie nie chciałoby go kupić.
Czy potrzebna jest mu jakaś forma zgody na wrzucenie „rękopisu” w bęben maszyny? Czy taka wrzutka stanowi naruszenie praw jego autora?
Wróciłbym do artykułu 16, czyli praw osobistych (na majątkowe będzie na tym etapie za wcześnie). Autor może między innymi decydować o pierwszym udostępnieniu utworu publiczności czy nadzorować sposób korzystania z utworu. Nie uważam, żeby w tym kontekście zastosowanie narzędzia od Literackiej było pierwszym udostępnieniem utworu publiczności — to właśnie to narzędzie wspiera w decyzji, czy takiego udostępnienia dokonać.
A czy jest to „sposób korzystania z utworu”? Tu przydadzą się już bardziej wyroki i komentarze innych autorów, ale najpierw – inne przepisy Prawa Autorskiego.
Art. 58 Jeżeli publiczne udostępnienie utworu następuje w nieodpowiedniej formie albo ze zmianami, którym twórca mógłby słusznie się sprzeciwić, może on po bezskutecznym wezwaniu do zaniechania naruszenia odstąpić od umowy lub ją wypowiedzieć.
Art. 49 – Jeżeli w umowie nie określono sposobu korzystania z utworu, powinien on być zgodny z charakterem i przeznaczeniem utworu oraz przyjętymi zwyczajami.
Mając dodatkowo te dwa paragrafy, sprecyzujmy zatem “korzystanie”. Jak mówi Wyrok Sądu Apelacyjnego w Warszawie z 5 czerwca 2018 (VI ACa 1561/16) jego istota sprowadza się do tego, “że autor powinien mieć możliwość weryfikacji, czy utwór jest udostępniany w zaakceptowanej przez niego postaci”. Utwór, a nie jego „obróbka” czy jakiś z niego „wyciąg” – taki jak efekt pracy oprogramowania od Literackiej.
Dodajmy do tego wyrok Sądu Najwyższego z 6 grudnia 2013 r. (I CSK 109/13):
Należy opowiedzieć się za szerokim rozumieniem zwrotu „rzetelne wykorzystanie utworu”, a wobec braku jego definicji legalnej uznać za wskazane sięgnięcie do kryteriów określonych w art. 49 ust. 1 u.p.a.p.p. Przepis ten ma charakter klauzuli generalnej, zastępującej dyspozycje stron umowy i zezwalającej na odtworzenie zakresu uprawnień korzystającego z utworu. Zgodnie z tym uregulowaniem, sposób korzystania z utworu powinien być zgodny z charakterem i przeznaczeniem utworu oraz przyjętymi zwyczajami.
Odnosi się on jak widać do wspomnianego wyżej art. 49, ale przede wszystkim zmusza nas do zastanowienia się nad zwyczajami czy zgodnością z charakterem i przeznaczeniem utworu. Nie oszukujmy się — przepuszczanie rękopisów przez sztuczną inteligencję póki co nie jest zwyczajem w tej branży 🙂 A czy jest zgodne z przeznaczeniem utworu? Według mnie tak — służy to przecież do jego lepszej dystrybucji, nie? Skoro już rękopis nie leży w tej symbolicznej szufladzie, tylko ma pójść w świat — przeznaczeniem jest dystrybucja i raczej jak najlepiej dopasowana do grupy odbiorców. Stąd odpowiednie przypisanie i ocenienie będzie tu w interesie zarówno wydawnictwa, jak i autora. I w mojej ocenie będzie spełniać rozumienie zgodności z przeznaczeniem.
Dodajmy jeszcze fragment wypowiedzi Ewy Laskowskiej (całość w „Konstrukcja ochrony prawnoautorskiej na tle procesu europeizacji prawa prywatnego”) omawiający właśnie rozumienie pojęcia „korzystania” użytego w prawie autorskim. Zgodnie z nim „autor uprawniony jest do sprawowania kontroli nad sposobem eksploatacji dzieła, tego, w jakim kontekście przedstawiany jest utwór, a także do kogo jest kierowany i czy jest to zgodne z zamierzeniem artystycznym twórcy”. To dla mnie potwierdzenie, że w tym korzystaniu mocniej jednak chodzi o przedstawianie na zewnątrz ostatecznej wersji utworu, niż jego wewnętrzną „obróbkę” i efekty w postaci raportu czy mapy.
Zwróć uwagę jeszcze na to: „Prawo do nadzoru nad sposobem korzystania z utworu wcale nie musi się odnosić docelowo do weryfikacji, czy treść i forma utworu nie zostały naruszone (możliwa do wyobrażenia jest bowiem taka sytuacja, w której twórca z przyczyn osobistych chciałby uzyskać dostęp do dzieła w celu np. inspiracji lub wykorzystania jakiegoś motywu w nowej pracy).”. Czyli intencja przepisu to bardziej malarz wpadający do muzeum i patrzący na sposób prezentacji swojego dzieła niż zabraniający muzealnikom jego analizy i opisania przed wystawieniem. I to już niezależnie: ręcznej, czy przy wsparciu zaawansowanej technologii.
Natomiast w razie co dałbym artyście możliwość jakiegoś sprzeciwienia się — trochę jak jest przy RODO, gdzie można odwoływać się od „maszynowej” decyzji do człowieka. To oczywiście nie wynikałoby z RODO, tylko uprzejmości i może ewentualnie art. 58 Prawa Autorskiego, który cytowałem wyżej. W każdym razie — choć wg mnie nie ma konieczności pytania o zgodę na wrzucenie czyjegoś utworu na ruszt sztucznej inteligencji w celu opracowania go przez nią, nie zaszkodzi na wszelki wypadek uwzględnić jej w umowie czy nawet na mailach. Albo po prostu uprzedzić o zamiarze takiego użycia.

Podsumujmy oba scenariusze
W pierwszym trenujemy model i wrzucamy mu mnóstwo utworów czy wycinków utworów, by się czegoś nauczył. Z powodów opisanych wyżej, temat nie jest ultra jasny, ale w uproszczeniu wygląda tak – w wielu przypadkach zgoda twórców nie będzie potrzebna, ale “nie zaszkodzi” jej uzyskać.
Podobnie wygląda to zresztą odnośnie pojedynczego utworu, który na powyższym wytrenowanym modelu będzie poddany obróbce i „zmieni się” w jakiś efekt. A jak z prawami autorskimi do tego efektu? O tym już rozmawialiśmy — na zakończenie zapraszam Cię do poprzedniego wpisu na ten temat.
Projekt „Asystent wydawniczy – oprogramowanie do analizy treści, wykorzystujące algorytmy sztucznej inteligencji w celu zautomatyzowania procesu wydawniczego i predykcji sukcesów rynkowych publikacji” otrzymał dofinansowanie Narodowego Centrum Badań i Rozwoju w ramach Programu Operacyjnego Inteligentny Rozwój 2014-2020.
O BookScout.ai przeczytasz więcej na stronie. Jeśli chcesz być na bieżąco i śledzić rozwój funkcjonalności systemu polub profil BookScout.ai na Facebook’u.
BookScout.ai służy zarówno wydawcom, jak i autorom. Oprócz analizy tekstu i rozpoznania jego kluczowych cech i parametrów, aplikacja ta usprawnia komunikację na linii wydawca – autor. Dzięki funkcjonalnościom BookScout.ai autor wie, na jakim etapie zapoznawania się z jego utworem jest dany wydawca i czy jest zainteresowany jego opublikowaniem.



